| n! x!(n − x)! |
, | der meist in Form des sogenannten Binomialkoeffizienten angegeben wird: | 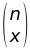
|
. |
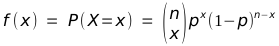
Im Folgenden werden drei häufig verwendete Wahrscheinlichkeitsverteilungen vorgestellt. Dabei handelt es sich eigentlich um drei Familien von Wahrscheinlichkeitsverteilungen, deren wesentlichen Eigenschaften durch die jeweils dazugehörigen Wahrscheinlichkeits(dichte)funktionen bestimmt sind. Die spezifischen Verteilungen innerhalb einer Familie unterscheiden sich in einem oder mehr Parameter (Argumente) dieser Funktionen, die man deswegen auch als Parameter der entsprechenden Verteilungen bezeichnet.
Binomialverteilungen sind diskrete Wahrscheinlichkeitsverteilungen; sie ergeben sich aus Zufallsexperimenten, die folgende Eigenschaften haben:
Das Standardbeispiel einer Binomialverteilung ist die Anzahl der Köpfe (oder der Zahlen) bei einer Reihe von Münzwürfen. Aber in vielen Arten von statistischer Untersuchung, wo man zwischen „Erfolg“ und „Misserfolg“ unterscheidet, kann die Binomialverteilung nützlich sein, z.B. bei der Wirksamkeit von Medikamenten aber auch beim Auftreten von Wörtern oder syntaktischen Konstruktionen in einem Korpus (wie wir später im Detail sehen werden).
Es mag von Interesse sein zu sehen, wie sich die Formel der Wahrscheinlichkeitsfunktion der Binomialverteilung mit x Erfolgen und n − x Misserfolgen aus den oben aufgelisteten Eigenschaften ergibt:
| n! x!(n − x)! |
, | der meist in Form des sogenannten Binomialkoeffizienten angegeben wird: |
|
. |
Die Verteilungsfunktion F(x) der Binomialverteilung ergibt sich aus einer Summe dieser Wahrscheinlichkeiten:
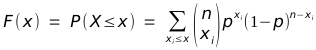
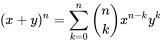
Die Zahlen n (Anzahl der Stufen des Zufallsexperiments) und p (Wahrscheinlichkeit des Erfolgs) sind die Parameter der Binomialverteilung. Bei der Angabe einer binomialverteilten Zufallsvariable sollten diese Parameter immer mit angegeben werden; eine geläufige Schreibweise ist die folgende:
Der Erwartungswert (das arithmetische Mittel) einer binomialverteilten Zufallsvariable X∼B(n, p) = np und die Varianz = np(1 − p) (und die Standardabweichung dementsprechend = √np(1−p) ). Diese Formeln lassen sich wie folgt ableiten:
Hier sind grafische Darstellungen von vier verschiedenen Binomialverteilungen:
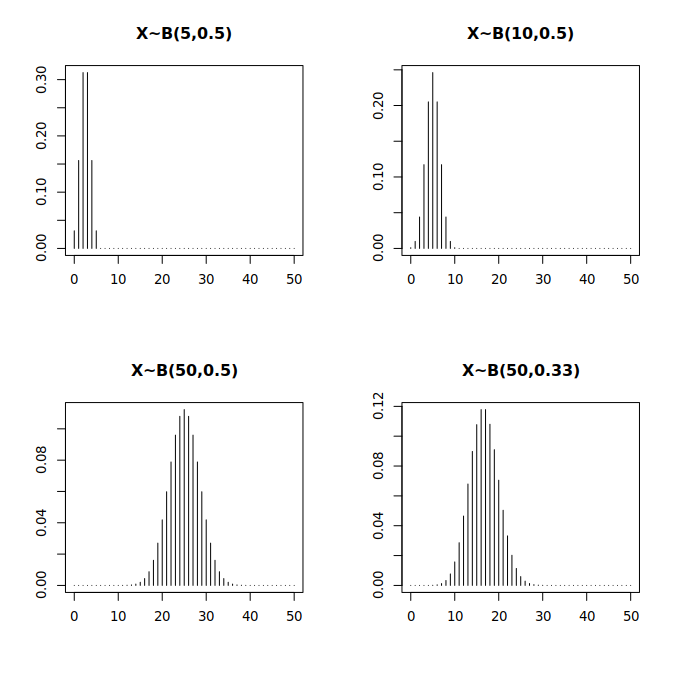
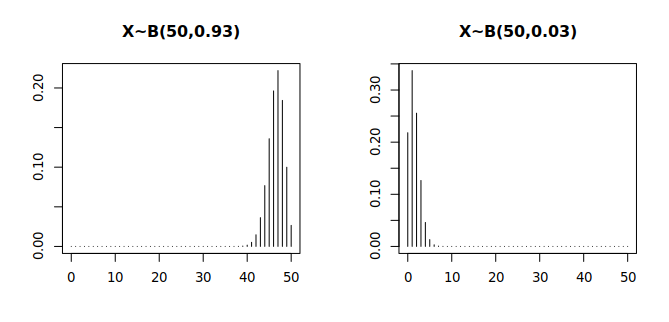
Abschließend weisen wir darauf hin, dass das sogenannte Galtonbrett eine sehr anschauliche (und in Videos mitunter auch unterhaltsame) empirische Demonstration des Zustandekommens der Binomialverteilung zeigt (bzw. als Annäherung dazu der Normalverteilung, der wir uns jetzt zuwenden).
Die Normalverteilung ist eine stetige Version von symmetrischen Binomialverteilungen. Ihre Entwicklung geht auf den Versuch zurück, eine rechnerisch handhabbare Abschätzung der Bionomialkoeffizienten zu finden, denn die darin vorkommenden Fakultäten sind außer bei kleinen Zahlen sehr rechenintensiv (selbst für moderne Computer). Die seinerzeit (ca. 1730) endeckte Abschätzung heißt die Stirlingformel: n! ≈ nne−n√2πn (vgl. die Wahrscheinlichkeitsdichte der Normalverteilung gleich unten).
Viele natürlich vorkommende Phänomene weisen annähernd eine Normalverteilung auf (z.B. die Verteilung der menschlichen Korpergröße). Darüber hinaus gibt es einen Satz der Wahrscheinlichkeitstheorie, den zentralen Grenzwertsatz, der zeigt, dass sich die Verteilungen der Mittelwerte von Stichproben bei zunehmender Größe (bzw. zunehmender Anzahl von Stichproben) einer Normalverteilung nähern, auch wenn die Verteilungen der Stichproben selbst nicht normalverteilt sind. Aus diesem Grund spielt die Normalverteilung eine wichtige Rolle in vielen statistischen Verfahren.
Die Normalverteilung ist eine Familie stetiger Wahrscheinlichkeitsverteilungen mit den Parametern μ (dem Erwartungswert der Verteilung) und σ (der Standardabweichung der Verteilung; manche Autoren verwenden die Varianz σ2 als den zweiten Parameter). Eine normalverteilte Zufallsvariable X∼N(μ, σ) hat folgende Wahrscheinlichkeitsdichte f(x) (π ist die Kreiszahl ≈ 3,14159 und e die Eulersche Zahl ≈ 2,71828):
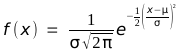
Die folgenden Grafiken zeigen die wesentlichen Eigenschaften der Normalverteilung und verschiedene Normalverteilungen, die sich in den Werten ihrer Parameter unterscheiden:
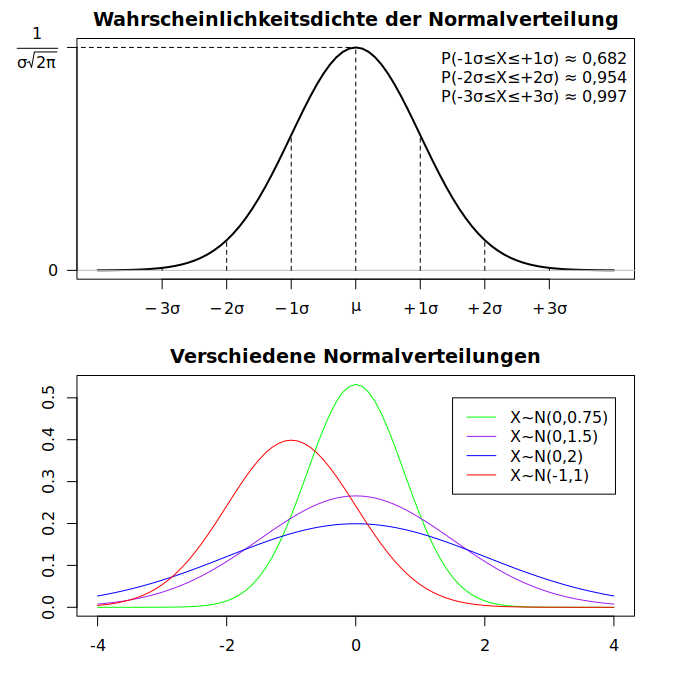
Bei jeder dieser Kurven ist der Prozentanteil der Fläche zwischen der Kurve und der x-Achse, die von sukzessiven Standardabweichungen unterhalb und oberhalb des arithmetischen Mittels bestimmt wird, immer derselbe: Plus/minus eine Standardabweichung beinhaltet ca. 68,2% der Gesamtfläche, plus/minus zwei Standardabweichungen beinhalten ca. 95,4% und plus/minus drei Standardabweichungen ca. 99,7% der Gesamtfläche. Da die Fläche unterhalb der Kurve dem gesamten Wahrscheinlichkeitsmaß entspricht, folgt daraus, dass es sehr unwahrscheinlich ist (ca. 0,03%), dass eine normalverteilte Zufallsvariable Werte hat, die weiter weg als drei Standardabweichungen vom Mittelwert liegen.
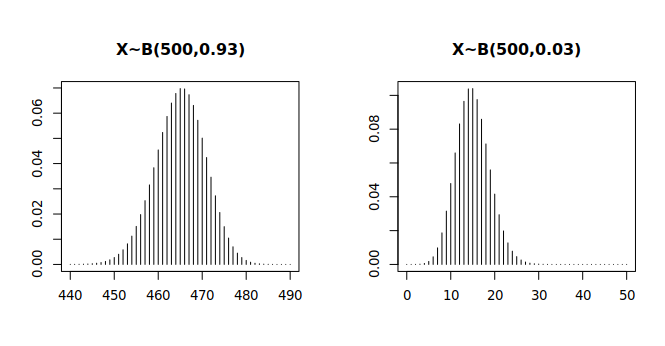
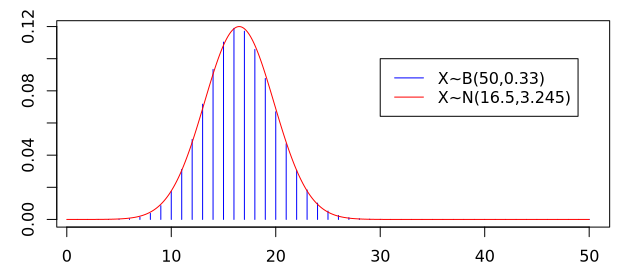
Für eine Binomialverteilung X∼B(n, p) kann die Normalverteilung Y∼N(np, √np(1−p) ) – also eine Normalverteilung mit dem Erwartungswert und der Standardabweichung der binomialverteilten Zufallsvariable als Parametern – u.U. eine gute Annäherung sein, wie die folgende Grafik veranschaulicht. Die Voraussetzung für die Güte der Approximation ist, dass n nicht zu klein ist und p weder zu klein (nahe 0) noch zu groß (nahe 1). Diese Approximation ist eine Folge des zentralen Grenzwertsatzes.
Jede Normalverteilung kann mit Hilfe folgender Formel in die Standardnormalverteilung umgewandelt werden:
| z | = | x − μ σ |
Als Beispiel berechnen wir z-Werte für vier Werte aus der obigen Normalverteilung X~N(16.5,3.245), also mit dem Erwartungswert 16,5 und der Standardabweichung 3,245: zuerst für eben diesen Erwartungswert, zweitens für den Wert, der der ersten größeren Standardabweichung entspricht, und schließlich für die Werte 15 und 20. Wenn wir diese Werte für x in die Standardisierungsformel einsetzen, ergeben sich folgende Gleichungen:
| 16,5 − 16,5 3,245 |
= | 0 | (16,5 + 3,245) − 16,5 3,245 |
= | 1 | 15 − 16,5 3,245 |
≈ | −0,46 | 20 − 16,5 3,245 |
≈ | 1,08 |
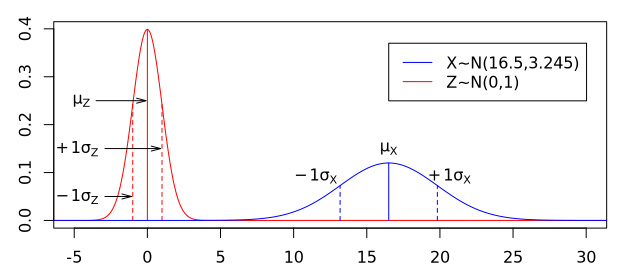
Da beide Verteilungen in derselben Skalierung dargestellt sind, sieht man deutlich die unterschiedlichen Streuungen: Die Standardabweichung der einen Normalverteilung ist über dreimal größer als die der Standardnormalverteilung. Dies führt dazu, dass der Graph Letzterer deutlich schmaler und beim Erwartungswert höher als der Graph Ersterer ist, was eine Folge der Definition von Wahrscheinlichkeit ist, wonach die Fläche unter der Kurve jeder Normalverteilung (vielmehr: unter der Kurve jeder stetigen Wahrscheinlichkeitsverteilung) immer = 1 ist.
Manuelle Berechnungen von Wahrscheinlichkeiten anhand der mathematischen Formel (d.h. der Wahrscheinlichkeitsdichte) der Normalverteilung sind aufwändig, deswegen wurden früher große Tabellen erstellt, in denen man viele ausgewählte Wahrscheinlichkeiten nachschlagen konnte. Diese Tabellen basieren auf der Standardnormalverteilung, enthalten also Wahrscheinlichkeiten nur für z-Werte (oder für Intervalle, die durch z-Werte bestimmt sind). Aber mit Hilfe der Standardisierung kann man solche Tabellen auch für Normalverteilungen mit anderen Parameterwerten nutzen. Wollte man z.B. für die Normalverteilung X~N(16.5,3.245) herausfinden, was die Wahrscheinlichkeit eines Wertes ≥ 20 ist, würde man in der Tabelle beim z-Wert 1,08 nachschauen, weil dieser Wert in der Standardnormalverteilung annähernd dem Wert in der fraglichen Normalverteilung entspricht, wie wir oben gesehen haben (das Ergebnis ist ungefähr 14%). Heutzutage werden solche Tabellen allerdings selten verwendet, denn man kann die Wahrscheinlichkeiten leicht mit Computerprogrammen wie z.B. R berechnen, wie wir sehen werden.
Eine weitere wichtige Familie stetiger Wahrscheinlichkeitsverteilungen ist die Chi-Quadrat-Verteilung, der die Standardnormalverteilung zugrundeliegt.
Die Chi-Quadrat-Verteilung (genannt nach dem griechischen Buchstaben χ und oft so geschrieben: χ2-Verteilung; die entsprechende Zufallsvariable wird meist als X2 geschrieben) ist definiert als eine Summe unabhängiger quadrierter standardnormalverteilter Zufallsvariablen Zi ∼N(0, 1):
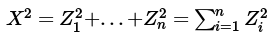
Die Anzahl n der standardnormalverteilten Zufallsvariablen ist der einzige Parameter der Chi-Quadrat-Verteilung und heißt die Freiheitsgrade der Verteilung (mehr zu diesem Begriff später). Die Zufallsvariable X2∼χ2(3) hat also eine Chi-Quadrat-Verteilung mit drei Freiheitsgraden. Die Anzahl der Freiheitsgrade bestimmt die Gestalt der Graphen der Wahrscheinlichkeitsdichte der Chi-Quadrat-Verteilung (diese Funktion ist zu komplex, um sie hier zu erläutern):
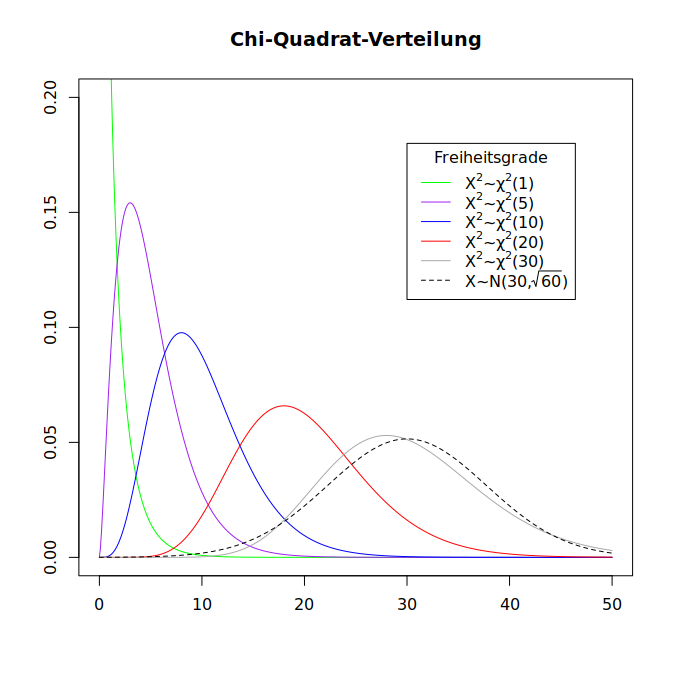
Diese Grafik deutet auf einige der Eigenschaften von Chi-Quadrat-Verteilungen hin:
Die Chi-Quadrat-Verteilung wird bei statistischen Auswertungen in der Korpuslinguistik häufig eingesetzt; verschiedene Beispiele werden wir später sehen.