Die Objekte einer statistischen Untersuchung (die sogenannten statistischen Einheiten der Untersuchung) haben in der Regel mehrere Merkmale, deren Ausprägungen für statistische Auswertungen relevant sein können. Eine Beobachtung ist eine Liste der jeweils festgestellten Ausprägungen der relevanten Merkmale einer statistischen Einheit. Ein Standardverfahren in empirischen Wissenschaften ist es, die Gesamtheit der Beobachtungen in tabellarischer Form festzuhalten, für die gilt:
In korpuslinguistischen statistischen Untersuchungen bestehen die Beobachtungen aus den Ausprägungen von Kombinationen folgender drei Arten von Korpusmerkmalen:
Solche Beobachtungen gewinnt man durch gezielte Anfragen in ausgewählten Korpora, d.h. die Beobachtungen ergeben sich aus den entsprechenden Treffern. Aus den Treffern und evtl. dazugehörigen Annotationen und Metadaten kann man Datensätze erstellen.
Datensätze kann man in R mit Hilfe der
Funktion data.frame() erstellen (der in R verwendete
Begriff für einen Datensatz ist data frame). Die Argumente
dieser Funktion sind Vektoren, die die Merkmale von Interesse für die
Untersuchung darstellen; die Elemente der Vektoren sind folglich die
jeweiligen Merkmalsausprägungen. Mit anderen Worten: Die Vektoren
stellen die Variablen der Untersuchung und ihre Werte dar, und bilden
die Spalten des Datensatzes. Wenn die Vektoren in R-Variablen
gespeichert sind und diese Variablen die Argumente
von data.frame() sind, dann bilden die Variablennamen die
erste Zeile des Datensatzes, die sogenannte Kopfzeile.
data.frame() auch Häufigkeitstabellen
erstellen kann. Häufigkeitstabellen sind Datensätzen formal ähnlich
aber inhaltlich stellen sie durch die Angaben der Häufigkeiten eine
Art Zusammenfassung von Einzelbeobachtungen dar, denn aus den
Einzelbeobachtungen kann man Häufigkeiten ohne Weiteres berechnen
(Beispiele werden wir später sehen).Normalerweise gibt man die beobachteten Werte aber nicht direkt als
Vektorenelemente in R ein, sondern die Daten werden i.d.R. zunächst in
Textdateien in einem tabellarischen Format festgehalten, das z.B. mit
einem Tabellenkalkulationsprogramm bearbeitet werden kann. Solche
Dateien können mit Hilfe von Funktionen wie read.table()
auch in R eingelesen werden und werden dadurch in Datensätze
umgewandelt, die anschließend genau wie mit data.frame()
erstellte Datensätze in R weiter verarbeitet werden.
In diesem Seminar werden wir Datensätze in R aus DWDS-Suchergebnissen
mit Hilfe einer eigenen Funktion erstellen,
die read.table() verwendet und sogar die DWDS-Suche
„unter der Haube“ durchführt, sodass man die DWDS-Website
gar nicht braucht. Details zu dieser Funktion gibt es
weiter unten, aber um besser zu verstehen, was
sie leistet, ist es sinnvoll vorher zu erfahren, was man ohne sie, also
nur mit DWDS und read.table(), dafür alles machen
müsste.
read.table()“ als
Hintergrundwissen betrachten: Sie sollten sie durchlesen, aber wir
werden in diesem Seminar Datensätze so nicht erstellen, sondern nur
mit der
Funktion dwds.data.frame().Wir haben gesehen,
dass DWDS tabellarisch formatierte Textdateien für die Ergebnisse
(Häufigkeiten) von Count-Anfragen sowie für Teilkorpusgrößen nach Dekade
und nach Textklasse zur Verfügung stellt. Aber auch die Suchergebnisse
normaler Anfragen stellt DWDS als formatierte Textdateien zur Verfügung,
die damit mit read.table() in R geladen werden können
(Details dazu gleich im nächsten Abschnitt weiter unten).
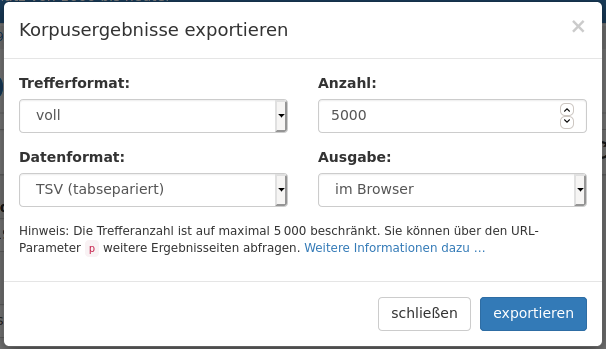
In DWDS kann man nach Durchführung einer normalen (also nicht Count-) Anfrage durch Klicken des Buttons „Treffer exportieren“ auf der Ergebnisseite (siehe dieses Bild) einen Auswahldialog aufrufen, mit dem man das Format und die Anzahl der Treffer (bis maximal 5000) und die Ausgabe entweder als Download oder im Browser auswählen kann. (N.B.: Um Suchergebnisse aus dem Korpus Archiv der Gegenwart zu exportieren, muss man sich in DWDS Anmelden; bei den anderen ohne Anmeldung verfügbaren Korpora ist der Export auch ohne Anmeldung möglich.) Folgendes Bild zeigt diesen Auswahldialog mit den für dieses Seminar geeigneten Einstellungen:
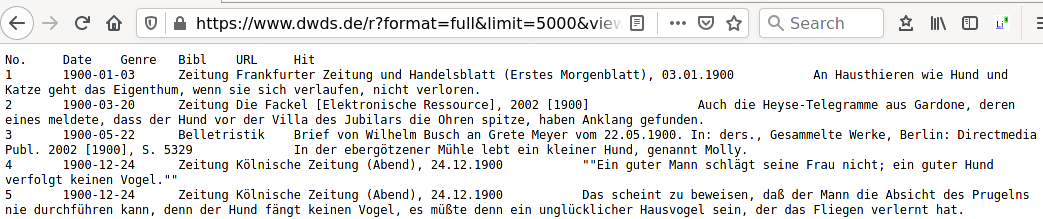
Hier ist ein Ausschnitt aus der DWDS-Ausgabe im Browser mit den oben gezeigten Einstellungen für die Anfrage ‚@Hund‘ im DWDS-Kernkorpus:

Zwar ist read.table() die wichtigste eingebaute R-Funktion
zum Einlesen von Datensätzen, aber für dieses Seminar ist es
praktischer, eine spezielle Funktion zu definieren,
die read.table() aufruft aber auch viele DWDS-spezifische
Anpassungen enthält. Diese Funktion, dwds.data.frame(),
wird im nächsten Abschnitt ausführlich beschrieben. Um ein vertieftes
Verständnis dieser Funktion zu gewinnen, erläutern wir einige Argumente
von read.table(), die in dwds.data.frame()
intern verwendet werden. Aber für dieses Seminar ist es nicht
erforderlich, solche Details zu wissen.
read.table()Die Funktion read.table() liest einen Datensatz
zeilenweise in R ein. Sie nimmt ein obligatorisches Argument und viele
optionale Argumente. Das obligatorische Argument
heißt file und spezifiziert die Quelle des Datensatzes.
Der Wert von file kann folgendermaßen angegeben werden:
choose.files() (die einen Datei-Auswahldialog
aufruft, aber nur unter MS-Windows) und file.choose()
(mit der man den Dateinamen nach Aufforderung in die R-Konsole
eingibt).Mit den optionalen Argumenten kann man das Einlesen sowie die Ausgabe des Datensatzes in R in vielfältiger Weise steuern. Für unsere Zwecke können bei den meisten dieser Argumente die voreingestellten Werte übernommen werden. Aber für folgende Argumente erfordern die DWDS-Daten Abweichungen von den Standard-Werten:
header: Dieses muss, wie wir beim Einlesen
von Häufigkeitstabellen
schon gesehen
haben, den nicht voreingestellten Wert TRUE haben, wenn
die erste nicht ignorierte Zeile des Datensatzes als die Kopfzeile
behandelt werden soll, was bei den exportierten DWDS-Datensätzen der
Fall ist.comment: Dieses bestimmt, welche Zeilen
des Datensatzes als Kommentare gelten und folglich von R ignoriert
werden. Der voreingestellte Wert ist das Zeichen "#", was im Falle
von exportierten Datensätzen aus Count-Anfragen und Teilkorpusgrößen
wünschenswert ist, wie wir auch beim Einlesen von Häufigkeitstabellen
gesehen haben. Beim Export von Datensätzen aus den Suchergebnissen
normaler Anfragen gibt es allerdings keine Zeilen, die ignoriert
werden sollen, und noch wichtiger: Für das Einlesen in R ist dieser
Wert problematisch, weil das Zeichen "#" Teil der DWDS-Daten oder
-Metadaten sein kann und in vielen Fällen auch ist. Wenn also R
dieses Zeichen als Beginn eines Kommentars verarbeitete, könnten
Spaltenwerte unvollständig eingelesen oder sogar das Einlesen ganz
verhindert werden. Daher sollte dieses Argument für Datensätze aus
DWDS kein Zeichen als Wert haben, also: comment="".sep: Dieses bestimmt, wie die eingelesenen
Zeilen des Datensatzes in Variablenwerte getrennt werden
(sep steht für separate, also trennen).
Standardmäßig wird nach jeder Folge von Leerzeichen, Tabulatoren oder
Zeilenumbrüchen getrennt. Für exportierte DWDS-Datensätze im
TSV-Format werden die Variablenwerte nur durch Tabulatoren getrennt,
daher müssen wir den Wert von sep darauf beschränken. In
R gibt man Tabulatoren mit dem Sonderzeichen "\t" an,
also: sep="\t".quote: Dieses bestimmt, ob Text in
Anführungszeichen von Text ohne Anführungszeichen unterschieden wird.
Standardmäßig wird Text mit Gänsefüßchen (") und Apostrophen (')
von Text ohne diese Zeichen unterschieden. Für unsere Zwecke ist
diese Unterscheidung nicht wünschenswert, weil wir die Treffer genau
übernehmen wollen, wie DWDS sie exportiert, daher unterbinden wir eine
Unterscheidung mit der Zuweisung: quote="".colClasses: Dieses bewirkt, dass R die
Spaltenwerte in einem Datensatz als bestimmte Datentypen behandelt.
Ohne dieses Argument können verschiedenen Werten unterschiedliche
Datentypen zugeordnet werden, aber für unsere Zwecke ist es am
praktischsten, mit colClasses="character" alle Werte als
Zeichenketten zu behandeln.
encoding: Dieses bestimmt, wie R die
Codierung des im Korpus verwendeten Zeichensatzes beim Einlesen
behandelt. Normalerweise geschieht das automatisch und man muss sich
nicht damit beschäftigen, aber beim Einlesen von einer Webseite über
eine URL kann es passieren, dass Zeichen wie z.B. Umlaute ohne Angabe
der Codierung nicht korrekt angezeigt werden. In DWDS wird die
Codierung UTF-8 verwendet, daher sollte beim Einlesen über eine URL
das Argument encoding="UTF-8" übergeben werden.Beispiel: 100 Treffer der Anfrage ‚@Hund‘ aus dem DWDS-Kernkorpus (mit den Sucheinstellungen: von 1900 bis 1999, in allen Textklassen und aufsteigend nach Datum sortiert) exportieren und in R als Datensatz einlesen:
read.table() enthält, in R durchführen:
> hund.kk.df1 <- read.table(file="https://www.dwds.de/r?format=full&limit=100&view=tsv&output=inline&q=%40Hund&corpus=kern&date-start=1900&date-end=1999&genre=Belletristik&genre=Wissenschaft&genre=Gebrauchsliteratur&genre=Zeitung&sort=date_asc", header=TRUE, comment="", sep="\t", quote="", colClasses="character", encoding="UTF-8")
Anmerkungen:
read.table() fehlschlägt, sollte man
folgende Anweisung eingaben und dann
den read.table()-Aufruf erneut ausführen:
> options(HTTPUserAgent="mozilla")
file darf keine Leerzeichen oder
Zeilenumbrüche enthalten.Um die ersten und letzten Zeilen des Datensatzes zu zeigen, kann man
die Funktionen head() bzw. tail() verwenden.
Die Darstellung hat allerdings einige Probleme, wie die folgende Ausgabe
der ersten drei Zeilen sowie der Kopfzeile von hund.kk.df1
zeigt:
> head(hund.kk.df1, n = 3)
No. Date Genre
1 1 1900-01-03 Zeitung
2 2 1900-03-20 Zeitung
3 3 1900-05-22 Belletristik
Bibl
1 Frankfurter Zeitung und Handelsblatt (Erstes Morgenblatt), 03.01.1900
2 Die Fackel [Elektronische Ressource], 2002 [1900]
3 Brief von Wilhelm Busch an Grete Meyer vom 22.05.1900. In: ders., Gesammelte Werke, Berlin: Directmedia Publ. 2002 [1900], S. 5329
URL
1
2
3
Hit
1 An Hausthieren wie Hund und Katze geht das Eigenthum, wenn sie sich verlaufen, nicht verloren.
2 Auch die Heyse-Telegramme aus Gardone, deren eines meldete, dass der Hund vor der Villa des Jubilars die Ohren spitze, haben Anklang gefunden.
3 In der ebergötzener Mühle lebt ein kleiner Hund, genannt Molly.
Solche Probleme sind neben den oben erwähnten DWDS-spezifischen Anpassungen weitere Gründe, eine eigene Funktion zum Einlesen von DWDS-Suchergebnissen in R zu definieren, die im Folgenden detailliert beschrieben wird.
dwds.data.frame()Weil die oben aufgelisteten optionalen Argumente
von read.table() immer jeweils denselben Wert beim Einlesen
von exportierten DWDS-Datensätzen haben sollen, kann man eine R-Funktion
definieren, die read.table() mit diesen Argumentzuweisungen
aufruft, was die Eingabe in R vereinfacht. Darüber hinaus ermöglicht
DWDS eine weitere Vereinfachung, denn mit der URL, über die die
tabellarische Ausgabe von DWDS-Suchergebnissen im Browser gezeigt wird,
wird auch die entsprechende Anfrage vorher ausgeführt.
Eine solche Funktion haben wir definiert, sie
heißt dwds.data.frame() und wird mit dem
bekannten source()-Aufruf
in R geladen. Diese Funktion nimmt folgende Argumente, die alle
optional sind (weil sie alle einen voreingestellten Wert
haben): Korpus, Anfrage, Start, Ende, Textklasse, Sortierung,
Zeilen, Abbrev. Die meisten dieser Argumente betreffen die Suche
in DWDS und entsprechen den verschiedenen Einstellungen in
der DWDS-Suchmaske (jedoch gibt es
kein Argument für die Anzeige als KWIC, voll oder maximal, weil wir
immer nur den vollen Satz des Treffers exportieren). Das
Argument Abbrev betrifft die Ausgabe in R, und das erste
Argument Korpus sowie das Argument Zeilen
betreffen sowohl die Suche als auch die Ausgabe, spielen also eine
doppelte Rolle. Hier ist eine Beschreibung der Argumente und ihrer
möglichen Werte im Einzelnen:
Korpus hat als Wert folgende zwei (sich
ausschließende) Möglichkeiten, die erste bezüglich der Suche und die
zweite bezüglich der Ausgabe:Zeilen bestimmt
wird, siehe unten) ein Datensatz gebildet und in R eingelesen
wird.Zeilen
(siehe unten); dabei werden die Werte der Spalten gemäß dem Wert
des Arguments Abbrev (siehe unten) ggf. gekürzt
dargestellt, damit die Anzeige möglichst innerhalb der Breite der
R-konsole bleibt.Korpus ist
"Kernkorpus".Anfrage, Start, Ende,
Textklasse, Sortierung werden nur dann verarbeitet, wenn der
Wert von Korpus einer der DWDS-Korpusnamen ist; das
Argument Abbrev wird nur dann verarbeitet, wenn der Wert
von Korpus eine Variable für einen Datensatz ist.)
Anfrage hat als Wert eine Anfrage, die
nach den Regeln der DWDS-Anfragesprache formuliert ist. Diese kann
eine beliebige DWDS-Anfrage sein, muss aber in einfachen oder
doppelten Anführungsstrichen eingeschlossen sein – nur in
einfachen, wenn die Anfrage selbst doppelte Anführungsstriche enthält
(also die 1. Variante einer DWDS-Anfrage
mit Abstandsangabe): z.B. "Hund"
oder 'Hund' aber nur ' "der #2 Hund" '.Start und Ende können als
Wert jeweils eine Jahresangabe haben, die für das früheste
bzw. späteste Erscheinungsjahr der Suchergebnisse im aktuell
eingestellten DWDS-Korpus (das der Wert des
Arguments Korpus angibt) steht, d.h. die Suchergebnisse
sind zwischen diesen Jahren (z.B. 1950 und 1990) erschienen.Textklasse kann als Wert einen Vektor haben mit
einem oder mehr der Ausdrücke "Belletristik", "Wissenschaft",
"Gebrauchsliteratur" oder "Zeitung" als Elemente (also
z.B. Textklasse = "Belletristik", Textklasse =
c("Wissenschaft", "Zeitung"), Textklasse =
c("Belletristik", "Wissenschaft", "Zeitung") usw.). Dieses
Argument wird nur berücksichtigt, wenn der Wert des
Arguments Korpus entweder "Kernkorpus", "Kernkorpus 21",
"DTA-Kernkorpus" oder "DTA-Erweiterungen" ist.Sortierung hat als Wert einen der folgenden
Ausdrücke (in Anführungsstrichen) : "Datum aufsteigend", "Datum
absteigend", "links aufsteigend", "links absteigend", "Fundwort
aufsteigend", "Fundwort absteigend", "rechts aufsteigend", "rechts
absteigend", "Beleglänge aufsteigend", "Beleglänge absteigend",
"zufällig". Dieser gibt die Art der Sortierung der Treffer an, die
DWDS vor dem Export durchführt.Zeilen hat als Wert verschiedene Möglichkeiten,
je nachdem, was für einen Wert das Argument Korpus hat:
Korpus der Name eines der oben
aufgelisteten DWDS-Korpora, dann hat Zeilen als Wert
eine Zahl, die bedeutet, dass höchstens so viele der Treffer
exportiert werden.Korpus eine Variable, die für
einen Datensatz steht, dann hat Zeilen eine der
folgenden fünf (sich ausschließenden) Möglichkeiten als Wert:
Zeilen = 6, Zeilen = 13 usw.),
dann werden die ersten n Zeilen des Datensatzes
ausgegeben.Zeilen = -6, Zeilen = -13
usw.), dann werden die letzten n Zeilen des Datensatzes
ausgegeben.c() oder mit
dem operator ‚:‘ gebildeter Vektor von Zahlen
(also z.B. Zeilen = c(6, 8, 13), Zeilen =
37:43 usw.), dann werden die entsprechend nummerierten
Zeilen des Datensatzes ausgegeben. Zeilen = "6", Zeilen = "13"
usw.), dann wird nur die eine entsprechend nummerierte Zeile
des Datensatzes ausgegeben.head()).
Abbrev hat als Wert zwei Möglichkeiten:
Es gibt drei weitere Besonderheiten von dwds.data.frame(),
einen die Suche und zwei die Ausgabe betreffend:
options(HTTPUserAgent="mozilla") ausgeführt, um
eine mögliche Fehlverbindung zu vermeiden. Nach dem Einlesen der
Daten wird diese Option zurückgesetzt (d.h., sie gilt nicht für einen
von dwds.data.frame() unabhängigen Aufruf
von read.table()). (Folglich müssen Sie bei der
Verwendung von dwds.data.frame() auf die eventuelle
Notwendigkeit dieser Eingabe nicht achten, anders als bei der
Verwendung von read.table().)Diese drei Begebenheiten finden automatisch beim Aufruf
von dwds.data.frame() statt, d.h. ohne die Übergabe eines
Arguments, also müssen Sie sich bei der Verwendung
von dwds.data.frame() nicht damit aufhalten.
dwds.data.frame()
> saetze.kk.df1 <- dwds.data.frame()
> nrow(saetze.kk.df1) # Anzahl der Zeilen im Datensatz
[1] 5000
Anmerkungen:
dwds.data.frame() ohne Argumente aufgerufen,
werden alle Voreinstellungen verwendet, das bedeutet: Die Anfrage
‚$.=0“ wird im ganzen DWDS-Kernkorpus (d.h. für alle Jahre
und alle Textklassen) durchgeführt und ein Datensatz mit 5000 Treffern
(Sätzen) in zufälliger Reihenfolge erstellt und in R eingelesen. (Das
kann schon mehrere Sekunden dauern, je nach der Netzverbindung.)read.table() muss der Rückgabewert
von dwds.data.frame() – also der neu erstellte und
eingelesene Datensatz – in eine Variable gespeichert werden, um
anschließend darauf zugreifen und damit arbeiten zu können.Im nächsten Beispiel wird dergleiche Datensatz wie
im obigen Beispiel mit read.table()
jetzt anhand von dwds.data.frame() mit dem ersten Aufruf
erstellt und mit den anschließenden Aufrufen in verschiedener Weise
ausgegeben:
> hund.kk.df <- dwds.data.frame(Anfrage = "@Hund", Sortierung = "Datum aufsteigend", Zeilen = 100)
> dwds.data.frame(hund.kk.df)
Nr. Datum Textklasse Quelle Treffer
1 1 1900-01-03 Zeitung Frankfurter Zeitung An Hausthieren wie H
2 2 1900-03-20 Zeitung Die Fackel [Elektron Auch die Heyse-Teleg
3 3 1900-05-22 Belletristik Brief von Wilhelm Bu In der ebergötzener
4 4 1900-12-24 Zeitung Kölnische Zeitung (A ""Ein guter Mann sch
5 5 1900-12-24 Zeitung Kölnische Zeitung (A Das scheint zu bewei
6 6 1900-12-31 Belletristik Duncker, Dora: Großs Wenn der Knüppel bei
> dwds.data.frame(hund.kk.df, Zeilen = -6)
Nr. Datum Textklasse Quelle Treffer
95 95 1904-03-03 Zeitung Berliner Tageblatt ( In einem Revier der
96 96 1904-03-04 Zeitung Berliner Tageblatt ( Ich hatte dem Prinze
97 97 1904-03-04 Zeitung Berliner Tageblatt ( Er hetzte einen ande
98 98 1904-03-04 Zeitung Vossische Zeitung (M Ich hatte dem Prinze
99 99 1904-03-04 Zeitung Vossische Zeitung (M Er hetzte einen ande
100 100 1904-03-04 Zeitung Vossische Zeitung (M Der Prinz sei oft fr
> dwds.data.frame(hund.kk.df, Zeilen = 37:42)
Nr. Datum Textklasse Quelle Treffer
37 37 1902-02-16 Zeitung Berliner Tageblatt ( Ueber einen entlaufe
38 38 1902-02-16 Zeitung Berliner Tageblatt ( Ueber einen entlaufe
39 39 1902-05-16 Belletristik Brief von Wilhelm Bu Ein Bilderbogen (Jun
40 40 1902-12-31 Gebrauchsliteratur Stettenheim, Julius: Denn es hieß viellei
41 41 1902-12-31 Gebrauchsliteratur Stettenheim, Julius: Das ist die Zeit, wo
42 42 1902-12-31 Belletristik Janitschek, Maria: D Die Mutter drückte s
> dwds.data.frame(hund.kk.df, Zeilen = c(6, 37, 58, 84))
Nr. Datum Textklasse Quelle Treffer
6 6 1900-12-31 Belletristik Duncker, Dora: Großs Wenn der Knüppel bei
37 37 1902-02-16 Zeitung Berliner Tageblatt ( Ueber einen entlaufe
58 58 1902-12-31 Belletristik Scheerbart, Paul: Im »Nu?« fragt der Hund
84 84 1903-12-31 Belletristik Reventlow, Franziska Im Hof schlug der Hu
> dwds.data.frame(hund.kk.df, Zeilen = "37")
Nr. Datum Textklasse Quelle Treffer
37 37 1902-02-16 Zeitung Berliner Tageblatt ( Ueber einen entlaufe
> dwds.data.frame(hund.kk.df, Zeilen = 3, Abbrev = 0)
Nr. Datum Textklasse
1 1 1900-01-03 Zeitung
2 2 1900-03-20 Zeitung
3 3 1900-05-22 Belletristik
Quelle
1 Frankfurter Zeitung und Handelsblatt (Erstes Morgenblatt), 03.01.1900
2 Die Fackel [Elektronische Ressource], 2002 [1900]
3 Brief von Wilhelm Busch an Grete Meyer vom 22.05.1900. In: ders., Gesammelte Werke, Berlin: Directmedia Publ. 2002 [1900], S. 5329
Treffer
1 An Hausthieren wie Hund und Katze geht das Eigenthum, wenn sie sich verlaufen, nicht verloren.
2 Auch die Heyse-Telegramme aus Gardone, deren eines meldete, dass der Hund vor der Villa des Jubilars die Ohren spitze, haben Anklang gefunden.
3 In der ebergötzener Mühle lebt ein kleiner Hund, genannt Molly.
Anmerkungen:
Abbrev = 0 zeigt eine
ungekürzte Ausgabe wie wie im obigen Beispiel
mit der eingebauten R-Funktion head(). Die einzigen
Unterschiede sind, dass mit dwds.data.frame() die
Spaltennamen auf Deutsch sind und die leere Spalte ‚URL‘
fehlt.Zum Schluss noch ein Beipiel für die Erstellung eines Datensatzes mit
nicht voreingestellten Werten für alle Argumente und drei verschiedene
Ausgaben davon (N.B.: bei der letzten Ausgabe ist Zeilenlänge aufgrund
des Arguments Abbrev = 40 zu groß für die Standardbreite
der R-Konsole (80 Zeichen), daher wird die Ausgabe der Treffer-Spalte
umgebrochen):
> hu.ka.dtae.df <- dwds.data.frame(Korpus = "DTA-Erweiterungen", Anfrage = '"Hund #5 Katze"', Start = 1770, Ende = 1880, Textklasse = c("Wissenschaft", "Gebrauchsliteratur"), Sortierung = "Beleglänge aufsteigend", Zeilen = 37)
> nrow(hu.ka.dtae.df) # Anzahl der Zeilen im Datensatz
[1] 37
> dwds.data.frame(hu.ka.dtae.df)
Nr. Datum Textklasse Quelle Treffer
1 1 1779 Wissenschaft Blumenbach, Johann F Nur Bäreu, Hunde, Ka
2 2 1782 Wissenschaft Blumenbach, Johann F Nur Bären, Hunde, Ka
3 3 1788 Wissenschaft Moritz, Karl Philipp Er aß Hunde, Katzen,
4 4 1854 Gebrauchsliteratur Das Pfennig=Magazin Die entleerten Telle
5 5 1855 Gebrauchsliteratur Das Pfennig=Magazin Daher ist die Feinds
6 6 1799 Wissenschaft Blumenbach, Johann F Bären, Hunde, Katzen
> dwds.data.frame(hu.ka.dtae.df, Zeilen = -6)
Nr. Datum Textklasse Quelle Treffer
32 32 1830 Wissenschaft Blumenbach, Johann F Außer dem Menschen a
33 33 1825 Wissenschaft Blumenbach, Johann F Außer dem Menschen a
34 34 1832 Wissenschaft Blumenbach, Johann F Außer dem Menschen a
35 35 1791 Wissenschaft Blumenbach, Johann F Der Floh findet sich
36 36 1825 Wissenschaft Pölitz, Karl Heinric Wann der, wie oft ge
37 37 1873 Gebrauchsliteratur Sanders, Daniel: Deu b. (s. 135 e) Nieman
> dwds.data.frame(hu.ka.dtae.df, Zeilen = 14:19, Abbrev = 40)
Nr. Datum Textklasse Quelle
14 14 1869 Gebrauchsliteratur Schweizer Alpen-Club (Hrsg.): Jahrbuch d
15 15 1854 Gebrauchsliteratur Das Pfennig=Magazin für Belehrung und Un
16 16 1782 Wissenschaft Blumenbach, Johann Friedrich: Handbuch d
17 17 1788 Wissenschaft Blumenbach, Johann Friedrich: Handbuch d
18 18 1788 Wissenschaft Moritz, Karl Philipp (Hrsg.): Gnothi sau
19 19 1805 Wissenschaft Blumenbach, Johann Friedrich: Handbuch d
Treffer
14 Da rief eine geisterartige Stimme von ob
15 Schweine, Hühner, Hunde und Katzen laufe
16 Der Floh findet sich auch auf Hunden, Ka
17 Der Floh findet sich auch auf Hunden, Fü
18 Auch hier trieb er seine Tollheit fort,
19 Sogar dass man zahlreiche Beyspiele von